

AI Panopticon: An Operating Memo on AI Trust
How the architecture of Mass Surveillance ended up inside your company's AI stack and what to do about it.


On February 24, 2026, Anthropic CEO Dario Amodei published a statement saying his company would not let Claude be used for mass domestic surveillance or fully autonomous weapons, even if it meant losing the Pentagon. Three days later, Trump banned Anthropic from every federal system, designated it a national security supply-chain risk, and OpenAI signed a deal to replace them. In 72 hours, Anthropic lost roughly $200 million in federal contracts and its entire government channel. It was the most expensive “where do we draw the line on AI?” decision any founder has made this year.
A lot has been said about Anthropic vs OpenAI over the last two weeks: the mass migrations, Claude hitting No. 1, the PR backlash, Sam’s habits, and OpenAI’s increasingly casual relationship with its own stated principles. It’s been treated mostly as AI Twitter drama.
I covered some of the surface‑level “what’s happening” here.
In this deep dive I want to discuss the technical reasons that Anthropic walked away: the behavioral surveillance and AI observability. what stack underneath the story, and what it implies for how we monitor people and systems inside our own companies, more about operating memo underneath those takes, focused on the actual architecture and trade‑offs, a conversation I don’t see many having yet.
Most founders read that story as a defense-industry soap opera. It isn’t. The technical architecture that the Pentagon wanted to build with Claude, fusing location data, communications metadata, financial records, and online behavior into real-time behavioral profiles of millions of people IS NOT some classified Pentagon prototype. Versions of it already exist inside your company’s AI stack. The same pipeline that powers “employee analytics” is architecturally identical to the one the Department of War tried to deploy against domestic populations. The only differences are jurisdiction, intent, and how long those differences hold.
This essay is to map that pipeline, understand where it lives in your company, and gives you three decision rules for staying on the right side of the line between AI observability and AI surveillance.
TL;DR / Content We are covering -
The Anthropic Precedent —> How one CEO’s refusal cost $200M in 72 hours and what it reveals about where AI observability ends and surveillance begins
What the Panopticon Actually Is —> Bentham’s prison, Foucault’s theory, and why AI just removed the one constraint that used to protect privacy
The Pipeline —> The 6-layer architecture behind AI mass surveillance, from raw data ingestion to automated action, and where LLMs actually sit
The Same Architecture Lives in Your Company —> Mapping the surveillance pipeline onto Slack analytics, productivity scoring, flight-risk models, and your HR stack
Two Philosophies of Control —> Anthropic’s “policy-in-the-weights” vs OpenAI’s “policy-in-the-platform” — and what this means for how you build
Behind the paywall -
Three Decision Rules for Founders —> Observe systems not people, the dossier test, and bidirectional auditability
The Ghost GDP Connection —> Why the Panopticon accelerates the doom loop from inside your org
What to Do Monday Morning —> The four-step audit you can run this week
1. What Just Happened (Founders’ Version)

If you strip away the discourse and look at it like an operator, the Anthropic–Pentagon blow‑up is a very specific kind of failure: a hard conflict between a customer’s desired capability and a vendor’s embedded constraints, resolved by swapping vendors rather than changing requirements.
Now there’ are three things that matter for us here -
The customer requirement was broad and future‑proofed.
The Department of War told Anthropic it would only contract with AI companies that allow “any lawful use” and remove vendor‑level carve‑outs for two categories:
mass domestic surveillance and
fully autonomous weapons.
In other words: “we don’t want the tool itself to tell us no, now or later.”
Anthropic’s red lines were baked into the product.
Amodei’s statement is clear: those two exclusions have never been in their DoW contracts, are grounded in the current technical limits of frontier models, and are not up for negotiation. They live in policy, in the safety stack, and in Claude’s behavior and
Anthropic refused to create a special backdoor for one customer, even the U.S. government.
The system routed around the constraint.
Faced with that impasse, the government didn’t narrow its requirement; it moved to designate Anthropic a “supply‑chain risk,” ordered agencies to off-board them, and began working with OpenAI on a replacement deployment that preserves nominal red lines via contracts and a configurable “safety stack.”
From a founder’s perspective, this is what it looks like when you ship a strong opinion as product. you don’t just lose a deal, you trigger a search for a vendor whose architecture and risk tolerance are compatible with the buyer’s ambitions.
What I care about in this essay is the content of that disagreement. The fight wasn’t over prompt wording or a marketing claim. It was over whether frontier models should be allowed to sit at the center of a pipeline that can:
fuse scattered data into comprehensive, person‑level behavioral profiles at population scale; and
feed those profiles into ranking and decision systems that drive surveillance and, in the limit, lethal force.
Once you understand / build that pipeline, you can see the same design questions showing up inside your company, just with different data sources and stakes.
2. What the Panopticon Actually Is
In 1791, philosopher Jeremy Bentham designed a prison called the Panopticon:
a circular building with a watchtower at the center.
Guards in the tower could see every cell. Prisoners could never tell whether they were being watched at any given moment. The design’s genius was that it didn’t require constant surveillance but only the possibility of it. Inmates disciplined themselves because they had to assume observation was continuous.
Michel Foucault turned this into a theory of modern power. His argument:
you don’t need a literal watchtower to get panoptic effects. Any system where people know they might be observed, and can’t tell when they are, can produce the self-discipline, conformity, and a slow erosion of autonomy. It is, as he wrote, “a way of making power relations function in a function.”
AI changes the math on this completely.

Before frontier models, surveillance was expensive.
You needed human analysts to read transcripts, review camera footage, cross-reference databases. Scale required headcount. That constraint is gone. A single LLM can now ingest movement data, communications metadata, financial transactions, and social media behavior, and synthesize it into a comprehensive behavioral profile of any person, automatically, at population scale.
The bottleneck that used to protect privacy, the sheer cost of paying attention to everyone has been removed.
ANd, that’s what Dario Amodei was talking about when he wrote:
“Powerful AI makes it possible to assemble scattered, individually innocuous data into a comprehensive picture of any person’s life — automatically and at massive scale.”
He wasn’t being hypothetical.
3. The Pipeline: How AI Surveillance Actually Works
If we strip away all the politics, and just focus on what the Pentagon wanted from Claude? It was a six-layer intelligence pipeline.
Every component of it exists today and is commercially available.
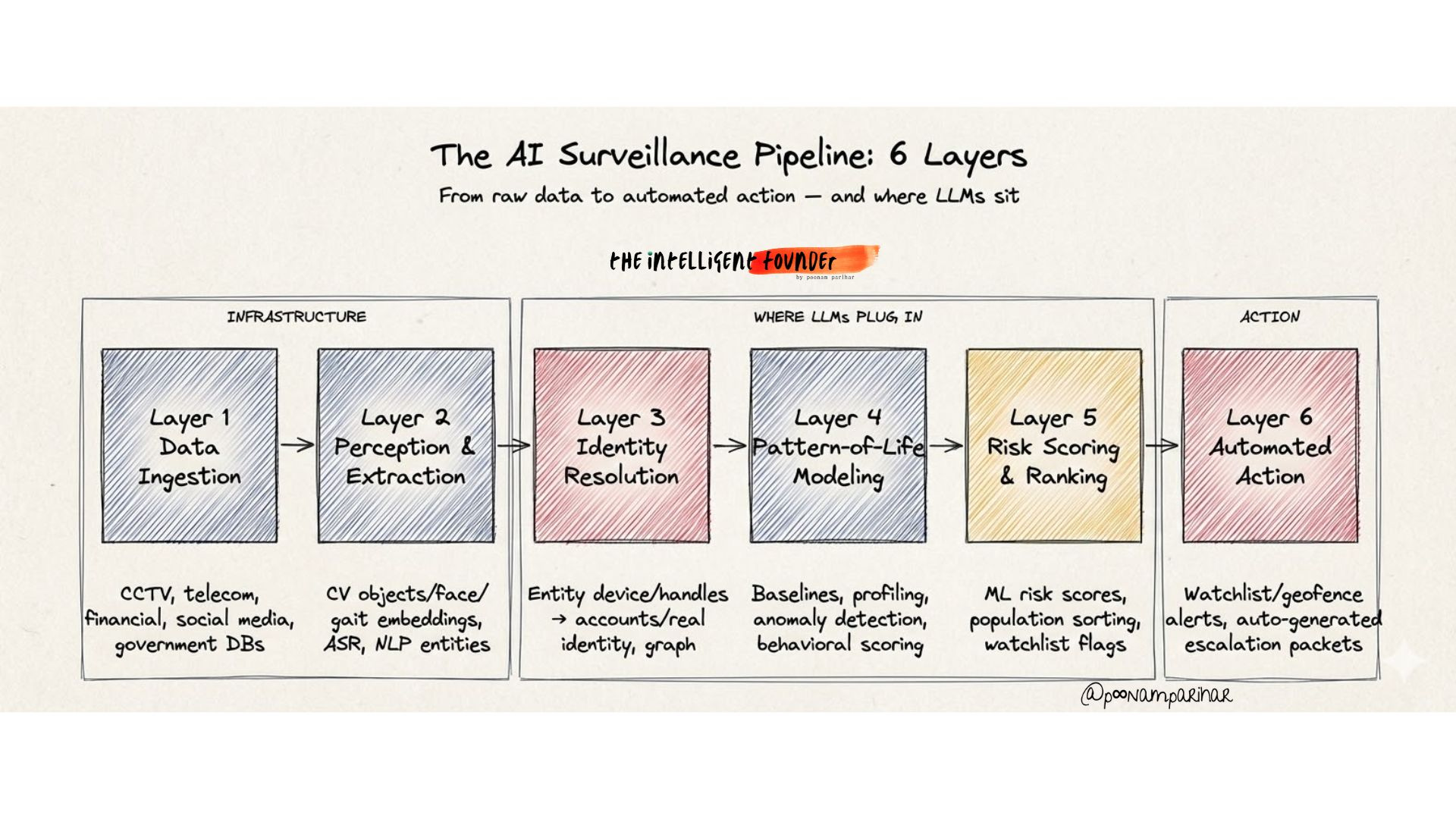
Layer 1: Data ingestion.
Raw feeds from cameras (CCTV, drones, traffic systems),
telecom metadata (cell tower pings, Wi-Fi probes, device fingerprints),
financial transactions,
social media scrapes, and
government records.
For a city of 10 million, this is billions of events per day flowing into a streaming data lake.
Layer 2: Perception and entity extraction.
Computer vision models detect and track people across video frames.
Biometric models generate face and gait embeddings.
Speech-to-text converts intercepted audio.
NLP extracts people, organizations, and locations from text.
The output is a continuous stream of structured events: »
✅ who,
✅ where,
✅ when,
✅ doing what,
✅ from which source.
Layer 3: Identity resolution and graph fusion.
This is the step that makes everything dangerous. A resolution layer links disparate identifiers, face embeddings, device IDs, social handles, bank accounts, license plates, government records, all in to a single persistent identity per person. The result is a massive knowledge graph where nodes are people and edges are relationships:
✅ who called whom,
✅ who stood near whom,
✅ who transferred money to whom.
A 2025 study published in Nature analyzing three decades of computer vision research found that 90% of papers and downstream patents involved extracting data about humans, and most targeting human bodies and body parts specifically. The study documented a 5x increase in computer vision papers linked to surveillance-enabling patents between the 1990s and 2010s.
This is not edge-case research. It is the mainstream of the field.
Layer 4: Pattern-of-life modeling.
Time-series models build routine profiles for every person:
✅ home,
✅ work,
✅ regular contacts,
✅ shopping habits,
✅ worship schedule.
Anomaly detection flags deviations >
✅ new locations,
✅ new associates,
✅ unusual hours,
✅ sudden changes in online behavior.
Layer 5: Risk scoring and population ranking
Machine learning models combine network centrality, routine deviations, content signals, and association patterns into a risk score for every individual. The population is sorted into tiers, from passive collection to active surveillance to intervention.
Layer 6: Automated action
And at layer 6 system generates outputs in the form of watchlists, geo-fenced alerts, auto-generated “escalation packets” with evidence summaries and recommended next steps.
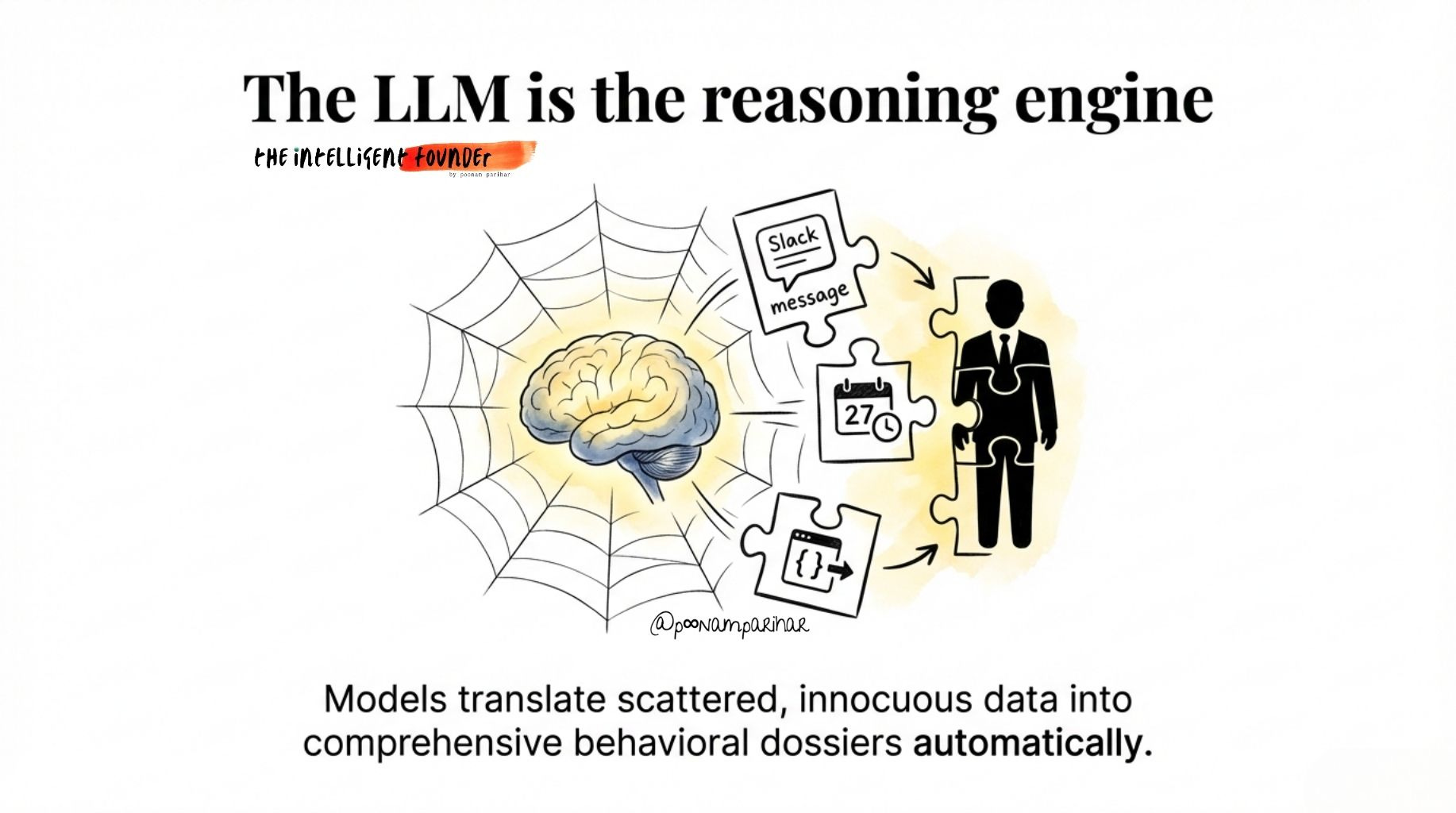
and Here is where the LLM sits: not at the camera or the cell tower, but at Layers 3 through 6.
The frontier model is the reasoning engine that makes population-scale analysis operationally useful. It translates natural language into multi-hop graph queries (”find everyone who attended the protest on Tuesday and has financial links to Organization X”).
It generates dossiers synthesizing hundreds of data points per person in seconds, for thousands of people simultaneously.
It narrates anomalies and writes escalation justifications that would previously require trained analysts spending days per case.
That’s the qualitative leap.
Before LLMs, mass surveillance required massive human analyst teams. With LLMs, you can generate comprehensive behavioral profiles for every person in a city, continuously, automatically. The constraint that used to protect liberty, the cost of attention as we said earlier and now repeat , well… » disappears.
4. The Same Architecture Lives in Your Company - Startup AI Panopticon
Now here’s the uncomfortable part. If you run a startup / company with more than 50 employees and any kind of AI-enabled tooling, you probably have a miniature version of this pipeline already running.

Lets Map it:
Layer 1 (ingestion): Slack/Teams messages, email metadata, calendar data, code commits, CRM activity, badge swipes, browser activity on company devices, application telemetry.
Layer 2 (extraction): Sentiment analysis on communications, meeting transcription and summarization, code review automation, activity tracking dashboards.
Layer 3 (fusion): HR platforms that cross-reference performance metrics with communication patterns, meeting attendance, response times, and project ownership. Some vendors now offer “flight risk” models that predict which employees are about to quit based on behavioral signals — email tone, meeting participation changes, training completion rates, calendar behavior.
Layer 4 (pattern modeling): Baseline productivity metrics per employee, deviation detection, “engagement scoring.”
Layer 5 (ranking): Performance stack-ranking informed by AI-analyzed behavioral data. Manager dashboards with per-person “productivity scores.”
Layer 6 (action): PIPs triggered by algorithmic signals. Retention interventions driven by flight-risk predictions. Hiring and firing decisions informed by behavioral models.
No single one of these tools looks like surveillance.
But the aggregate of the Slack analytics plus calendar scoring plus code-commit tracking plus meeting sentiment analysis plus flight-risk modeling, is a your corporate Panopticon. The unit of analysis has quietly shifted from systems to people. and what happens next is very clear.
Cornell found that employees subjected to AI-driven monitoring reported significant loss of autonomy, engaged in more resistance behaviors (performing worse, complaining more, intending to quit), and generated fewer ideas during creative tasks.
AI monitoring specifically triggered greater negative reactions than human monitoring.
The paradox:
Non-invasive monitoring tools can boost measurable activity by 40%+ within days of deployment. But when you look closer, you’re buying compliance, not engagement.
Employees are performing for the system that is made of jiggling mice, padding activity metrics, gaming whatever the algorithm measures and not doing better work.
49% of monitored workers admit to faking being online.
54% say they’d consider quitting over increased surveillance.
68% oppose AI-powered monitoring specifically.
So in return you get dashboards that look great and an organization that’s slowly hollowing out.
5. The Anthropic Precedent: Two Philosophies of Control

The Anthropic-Pentagon showdown is actually a clean test case of a decision every technical founder faces.
Anthropic’s says that: certain capabilities are hard-coded as off-limits in the model itself. Claude’s alignment training, safety classifiers, and acceptable use policies make it fundamentally resistant to mass surveillance and autonomous weapons tasks, and Anthropic refuses to remove those constraints for any customer, including the U.S. government.
The red lines live in the product, not just the contract.
They survive changes in administration, changes in law, and changes in customer intent.
OpenAI’s position is to deploy the models with a “safety stack” meaning a configurable layer of policy engines, system prompts, role-based access controls, and human-in-the-loop requirements “which can be” NEGOTIATED into the contract.
Sam Altman wrote that the Pentagon deal includes -
“prohibitions on domestic mass surveillance and human responsibility for the use of force, including for autonomous weapon systems,” and that the Pentagon “agrees with these principles, reflects them in law and policy, and we put them into our agreement.”
Same headline principles.
Fundamentally different architectures of trust.
