

DeepSeek V4 Is Coming 🚀. Your AI Budget Isn't Ready. ⚠️
The specs are real. The hype is loud. Here's what actually holds up and what you should do about it.

The AI world is holding its breath. Again.
DeepSeek, the Chinese lab backed by hedge fund High-Flyer that triggered a $600 billion single-day Nvidia selloff in January 2025, is about to drop its next-generation model. V4. A trillion parameters. Native multimodal. One million token context window. And as of March 12, nobody outside a handful of NDA-gated testers has run independent benchmarks on it. I did this initial research on March 9th late night GMT, and the model originally planned for first week of March was only limited released until then, but a few things have moved in past three days, for example, V4 pricing is now being reported by several infra providers, so we’re no longer guessing at rough orders of magnitude, and we do have real ballpark numbers, even if DeepSeek hasn’t blessed them yet.

A couple of good summary pages have also appeared that do line up with the core story here: ~1T parameters, a smaller “V4 Lite” around a few hundred billion, 1M context, multimodal, and clear signals that it’s tuned for Chinese chips.

DeepSeek’s own site now shows a “V4 Lite” label, which is the first on‑platform sign that the rollout is close, at least for the smaller variant. At the same time, some blogs are already writing “as if V4 is fully launched” and quoting very specific benchmark numbers;I dont have the model card yet, no announcement either so I am treating them as unverified and in “rumors and leaks” bucket rather than as facts.
To summarize quickly, here’s what the chatter looks like right now:
Reuters reported DeepSeek withheld V4 from Nvidia and AMD, giving Huawei and Cambricon first access instead.
Financial Times confirmed V4 will be native multimodal ie - text, image, and video generation. so a massive upgrade from the text-only V3
In the meantime both Anthropic and OpenAI have accused DeepSeek of “industrial-scale distillation” using thousands of fake accounts to extract knowledge from Claude and ChatGPT.
Several infrastructure providers now list preliminary V4 API pricing, and a “V4 Lite” label appeared on DeepSeek’s own site on March 9.
Prediction markets had an 88% probability on a March release. We’re 12 days in. and still waiting for an official announcement.
Meanwhile, DeepSeek has said... absolutely nothing.
SO the headline game is loud but the actual verified information is thin. And that gap is exactly where founders need to pay attention, precisely why I am doing this research and why this deep-dive is going out today.
A lot has already been written about V4, but almost all of it is incomplete.
The best technical deep dives are written for ML engineers.
The policy analysis is written for the regulators. and,
The mainstream coverage is all geopolitics » Nvidia drama, distillation accusations, ban lists etc.
What’s missing or at least what i couldn’t find was what could stitch architecture, economics, geopolitics, and a concrete playbook into a single analysis for people who actually have to make decisions. so I am doing that here, with what I can see is confirmed, or strongly suggested, and speculative claims, so you/I know exactly where the ground is solid and where it’s still shifting.
What This Article Covers
🔍 What we actually know about V4 —» specs, architecture, release status, all fact-checked
🧠 The three big technical bets —» Engram O(1) memory, sparse MoE, and 1M context
🌏 China’s parallel AI stack —» domestic chips, export controls, bans, and the distillation controversy
💰 The economics behind it —» real pricing comparisons showing why even conservative estimates change your cost structure
🛡️ The risk layer —» safety gaps, compliance realities, and the self-hosting middle path, and
🎯 The founder playbook —» 7 concrete moves for the next 12–24 months
Let’s go.

1. What we know about DeepSeek V4 so far!
Here’s what holds up after pulling apart every credible source such as Reuters, FT, published papers, code commits, infrastructure provider listings, and developer community analysis.
The model was originally targeted for mid-Feb 2026, Lunar New Year, mirroring R1’s symbolic holiday release from January 2025. but It was delayed. FT the reported that CEO Liang Wenfeng was “dissatisfied with the results”. Another complication reported was that DeepSeek tried training on Huawei’s Ascend chips under pressure from Chinese authorities, and hit persistent hardware failures, and so had to revert to Nvidia GPUs for training.
On February 11, DeepSeek silently upgraded its existing models from 128K to 1 million token context which got widely interpreted as V4 infrastructure being tested in production. TechNode reported on March 2 that V4 would launch “this week” but It din’t and later on March 9 after I did my initial research that is, a “V4 Lite” label appeared on DeepSeek’s site. The important part however is that several infrastructure providers have now listed preliminary V4 API pricing.
Here’s all the data confirmed / suggested / reported.
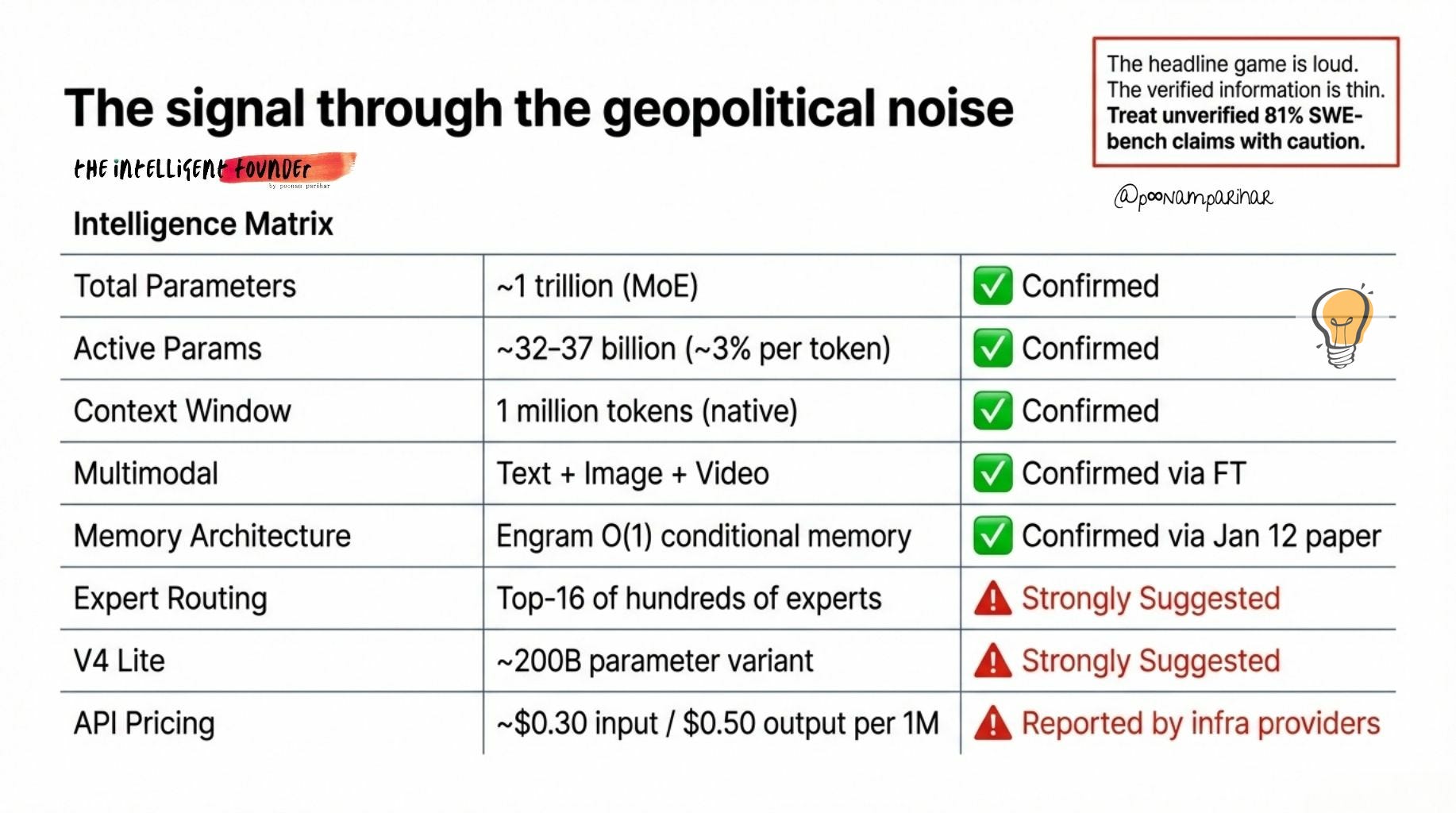
Some blogs have begun writing as though V4 is fully launched, quoting benchmark figures like 81% SWE-bench Verified. i couldn’t verify that.
There’s also some chatter about naming. V4 is the base/chat model (successor to V3). R2 is the reasoning model (successor to R1). so they’re separate products. R2 was originally targeted for May 2025, then August, and still hasn’t shipped.
Some prediction markets are now tracking “V4-Thinking” as possibly being R2 under a different name.

2. The Three Big Technical Bets
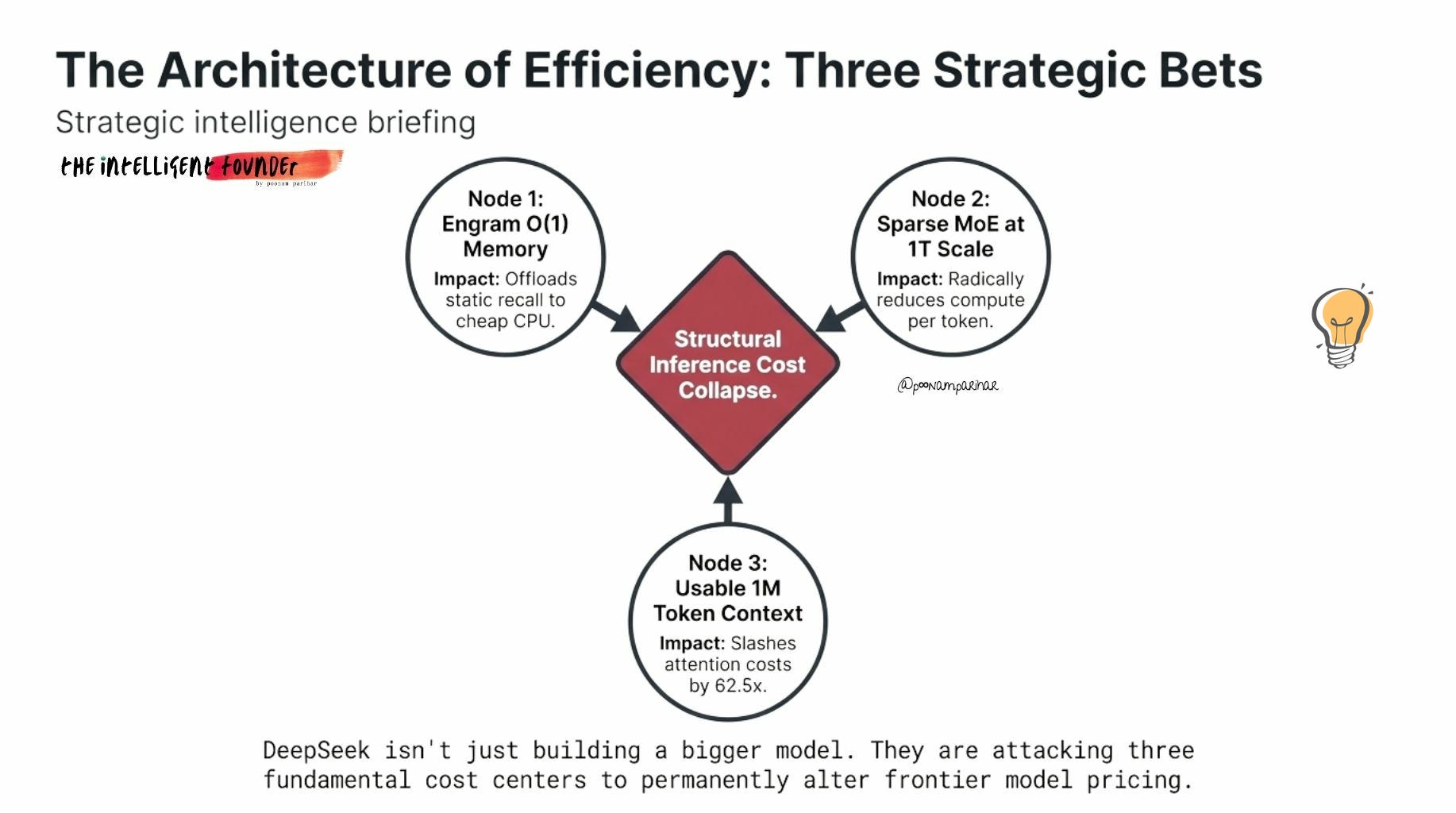
Now this is where the V4 gets interesting, and important. its not because of scale, but because of architecture, and why I thought of doing this deep dive at the first place. DeepSeek isn’t just building a bigger model. They’re trying to solve three fundamental problems that every frontier model struggles with.
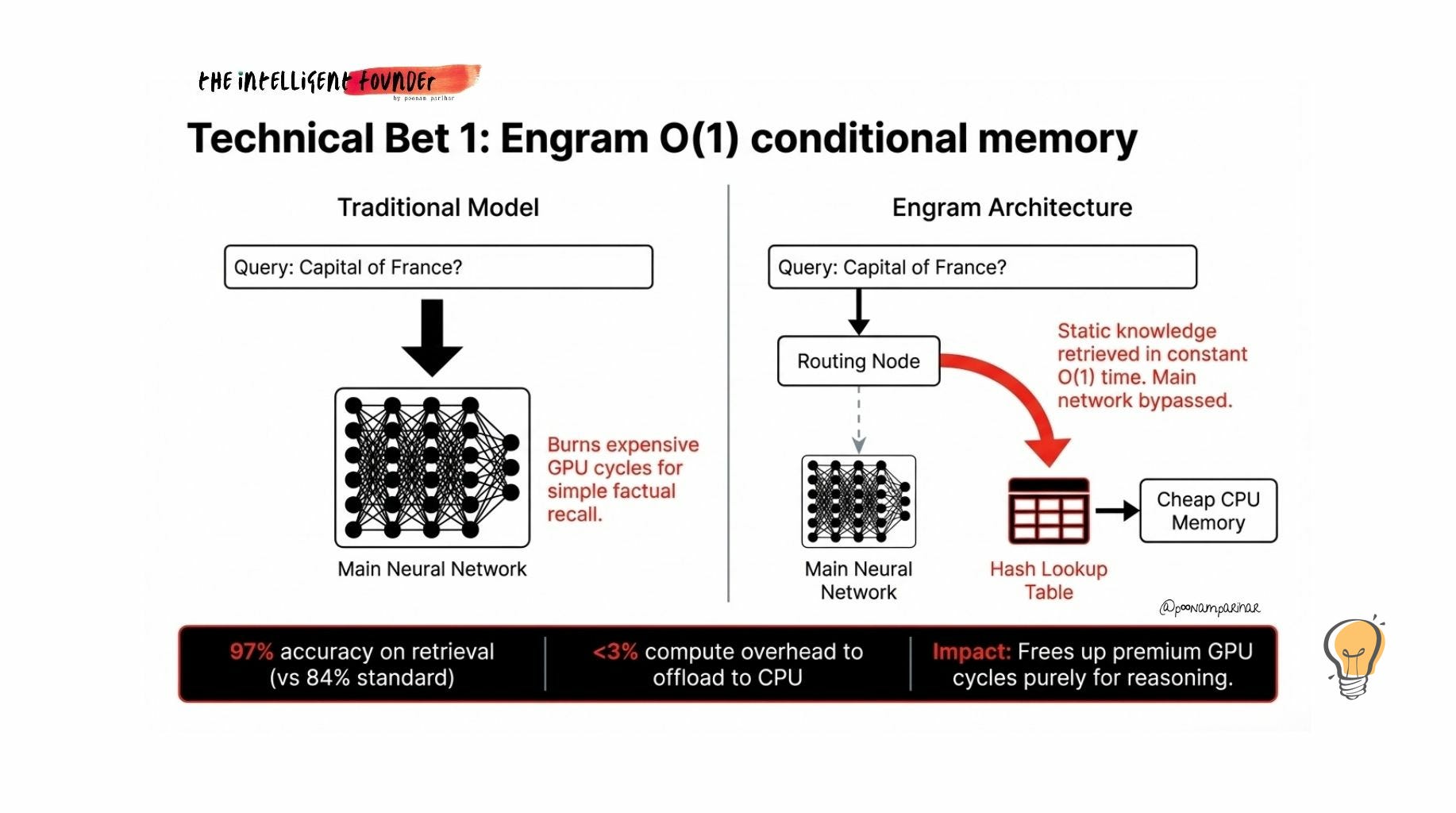
Bet number 1: Engram - O(1) Memory
Traditional AI models use the same expensive neural network for everything. whether you’re asking “what’s the capital of France?” or “design me a distributed database architecture.” Simple factual recall burns the same GPU cycles as complex reasoning. That’s wasteful.
Engram adds a separate dictionary to the model. A hash-based lookup table where static knowledge lives, things the model has seen a million times during training. When V4 encounters a pattern it recognizes, Engram retrieves the answer in constant time called O(1), meaning the cost doesn’t increase with context length and the expensive neural network is freed up for actual thinking.
How it works in practice?
text gets normalized and broken into small fragments (2-grams and 3-grams).
Multiple hash functions map these to entries in a massive lookup table.
A gating mechanism filters out noise
if the retrieved knowledge conflicts with what the model is currently working on, the gate suppresses it.
Retrieved values merge back into the main processing stream.
The published results (Engram-27B vs a standard MoE baseline with the same parameter count):
+5% on Big-Bench Hard reasoning tasks,
+12.8% on Multi-Query Needle-in-a-Haystack (finding specific information buried in long contexts), and
97% accuracy on retrieval vs 84% for standard architectures.
the lookup table gets offloaded to cheap CPU memory with less than 3% overhead, which means your GPU stays free for the hard stuff.
What’s still unclear however?
Engram is published as a research paper, and code references exist in DeepSeek’s repositories. But whether it’s fully integrated into V4’s final release isn’t confirmed.
V4 Lite reportedly does not include Engram.
And retrieval quality for ambiguous or context-dependent patterns at trillion-parameter scale is unknown.
Bet number 2: Sparse Mixture-of-Experts at 1T Scale
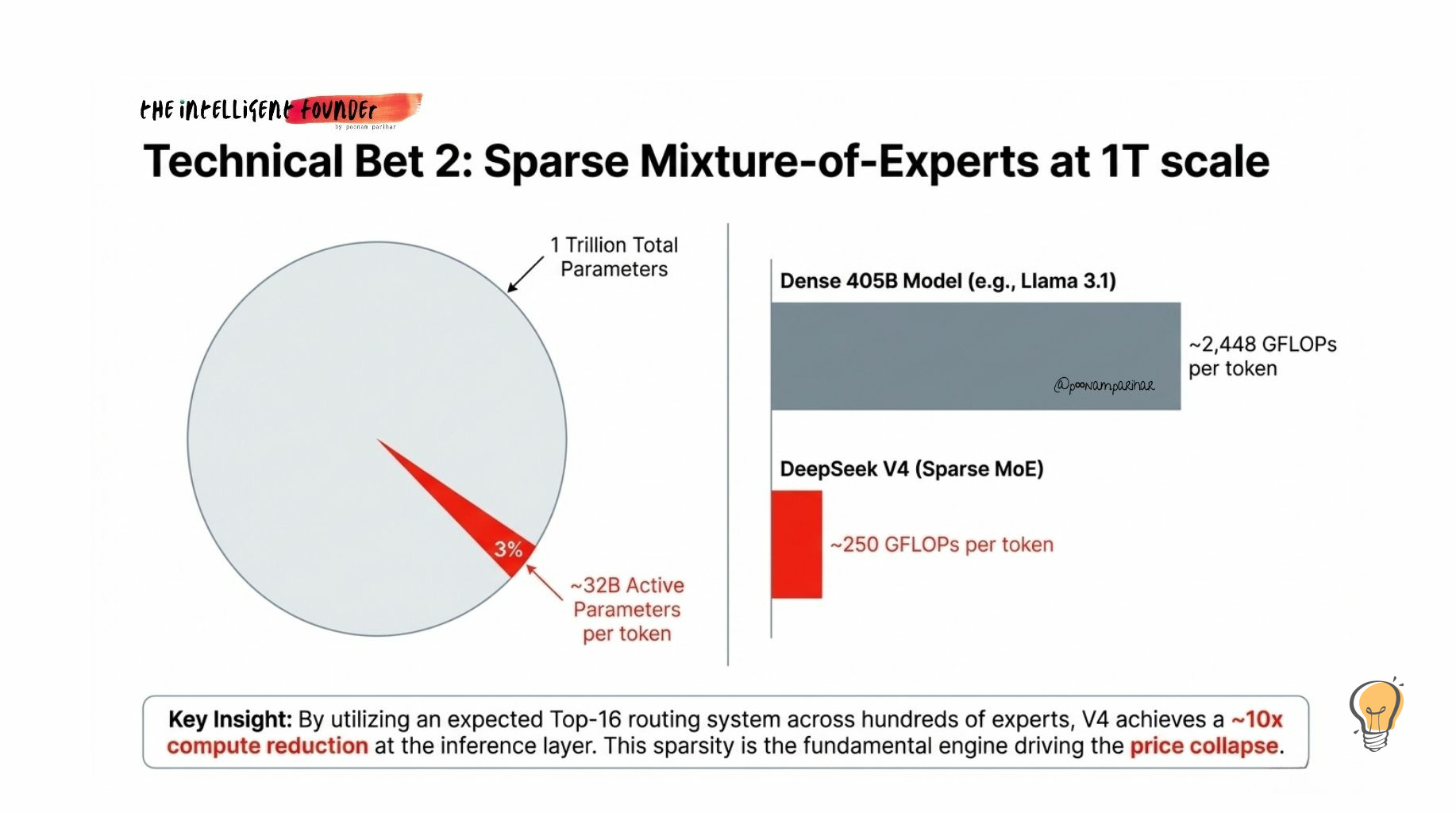
V4 has roughly 1 trillion total parameters, but only ~32–37 billion activate for any given token. That’s a ~3% activation rate.
Why this matters?
A dense model with 1T parameters would be absurdly expensive to run. Sparse MoE means V4 uses approximately 250 GFLOPs per token vs ~2,448 GFLOPs for a dense 405B model like Llama 3.1. That’s roughly a 10x compute reduction at the inference layer and the fundamental reason DeepSeek can price at a fraction of What western frontier models costs.
DeepSeek has been iterating on MoE across generations, starting with 64 experts and Top-6 routing, moving to 256 experts and Top-8 in V3, and now expected to use Top-16 routing across hundreds of experts in V4.
Routing instability (where a few experts get overloaded while others sit idle) is a known MoE failure mode. DeepSeek uses hierarchical routing and “noisy routing” during training to prevent this. But at trillion-parameter scale with Top-16 routing, it becomes harder to manage, and creates a specific security vulnerability which we’ll get to later. so the trade-offs are very real.

Bet 3: 1 Million Token Context (That’s Actually Affordable)

Here’s what 1M tokens can get you in practice:
~50,000 lines of code in a single context (enough for whole-repo understanding),
multiple legal contracts loaded simultaneously for cross-reference analysis, or
extended agent operations where the model maintains coherence across hundreds of steps.
But raw context length alone isn’t the story. The real innovation is making it affordable.
Standard attention scales quadratically ie double the context, quadruple the compute. DeepSeek’s Sparse Attention (DSA) identifies just 2,048 of the most relevant tokens from the full context, cutting attention cost by roughly 62.5x. Now this combined with a tiered KV cache that pushes less-accessed data from GPU to CPU to disk, V4 achieves a claimed 40% memory reduction while supporting 1M+ tokens.
Plus, DeepSeek recently published DualPath, a system for solving I/O bottlenecks in long-context agentic inference, improving throughput by up to 1.87–1.96x.
This is expected to be part of V4’s inference stack.
This is exactly why this architecture combination matters:
Engram handles static recall at O(1),
DSA handles selective attention at roughly O(n) instead of O(n²), and
sparse MoE keeps per-token compute at ~32B parameters.
Three different sparsity mechanisms, each attacking a different cost centre.

3. China’s Parallel AI Stack: What’s Actually Happening
This is the section where most commentary gets it wrong. its either overstating China’s independence or understating the strategic intent. The reality however is much more messier and interesting than either narrative.
The Facts on the Ground
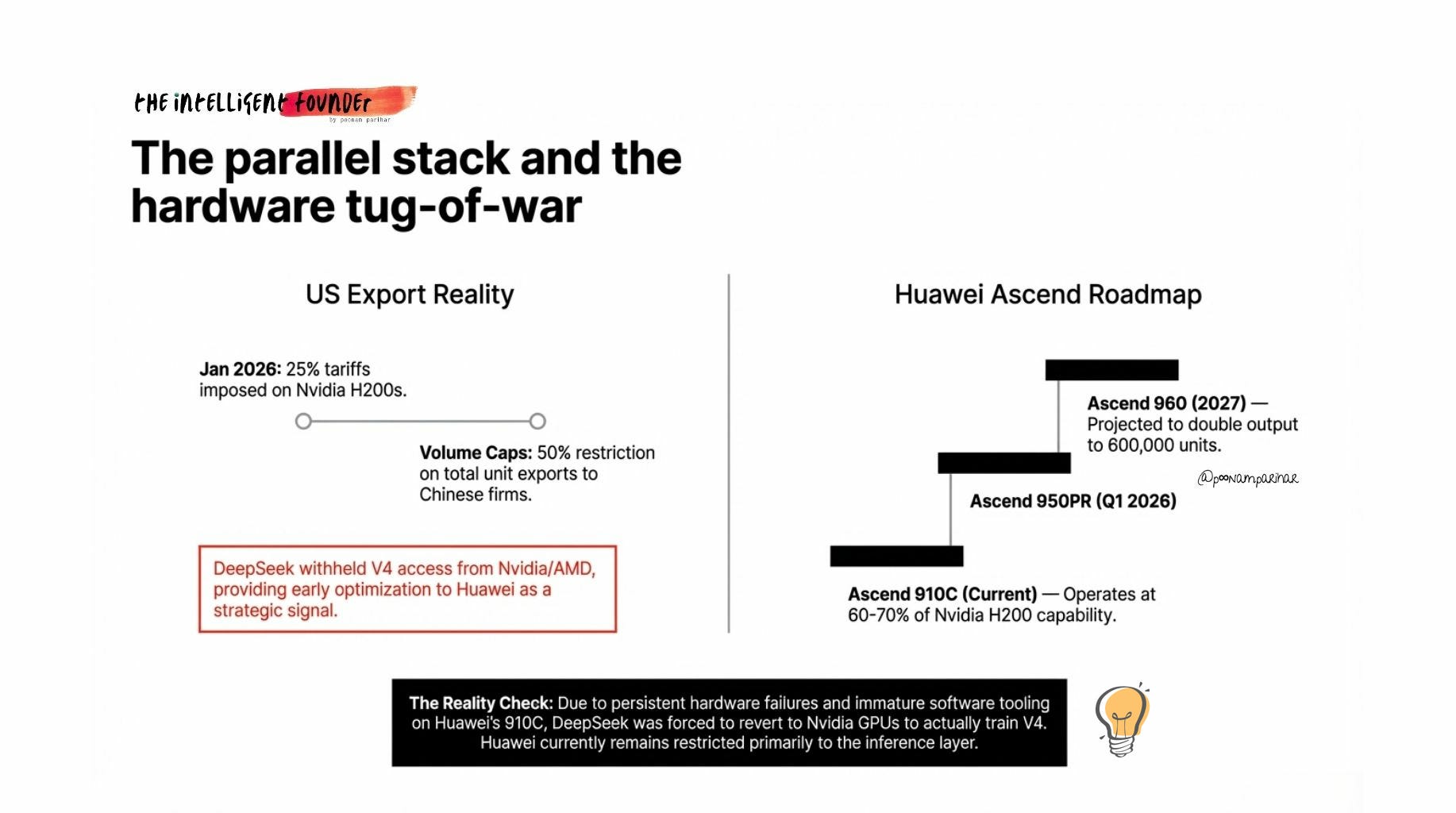
DeepSeek withheld V4 from Nvidia and AMD. Reuters confirmed that DeepSeek gave early optimisation access to Huawei and Cambricon instead of its traditional Nvidia partners. This is a deliberate strategic signal — not a technical necessity.
( The Intelligent Founder is a reader-supported publication. The technical deep dive sections of this article (Sections 4–8) are available to paid subscribers. To receive the full playbook and support independent analysis, consider upgrading.
If you found this useful, share it with a founder who’s still paying $25/1M output tokens without asking why.)

