

The AI Moat is Dead!
Commoditization and Strategy in the DeepSeek V4 Era.

Six weeks ago I wrote this below deep dive about DeepSeek V4 when it was about to be released but was held back. we got the specs that were real, it looks like most AI budgets were structurally unprepared for what was coming. Prediction markets were sitting at 88% probability of a March release. But DeepSeek had other ideas.
Now my whole argument was about how DeepSeek V4 is going to be a real architectural and economic shock to the AI market. how it makes frontier‑level capabilities dramatically cheaper by combining Engram memory, sparse MoE, and 1M‑token context, and that cost collapse will force every serious builder to rethink their stack, pricing, and moat strategy, and I said all this while both Anthropic ( frontier AI) and Nvidia ( open-weight) released 1M-token context models in the same week, pressure or not, we’ll discuss later.
My own strategy and advice to founders? » treat models as commoditizing infrastructure, route everything through an abstraction layer, build your moat around data and workflows, and be ready to evaluate and switch quickly as V4 and its peers reset the competitive floor on AI costs.
DeepSeek V4 finally dropped yesterday morning. its still in preview mode but good enough details available to run an honest scorecard, take the temperature of the room, map the competitive landscape properly, and then go to the angles we discussed before and what I dont’ see most focus on despite of so much chatter on X/twitter. as expected, the spec sheet is the least interesting part of this whole story.
Table of Contents
The Scorecard: What I Got Right, What I Got Wrong
Architecture, pricing, open source, confirmed. Timeline and GA status?The Room: What the Internet Is Actually Saying
X, Hacker News, Reddit - the human temperature on launch day.The Competition: 1M Context Is Now Table Stakes
Anthropic, NVIDIA Nemotron 3 Super, Qwen 3.6 Plus, GPT-5.5 - the full landscape.The Chip Story: The Real Reason It Was Six Weeks Late
Smuggled Blackwells, Huawei Ascend 950PR, Jensen Huang’s warning.The Distillation Controversy: Building on the West’s Shoulders
Claude and ChatGPT outputs, ToS violations, the legal question nobody has resolved.The Multimodal Blindspot: This Is Not a Text Model
Native text + image + video from pre-training - what this changes for enterprise workflows.RAG Is Not Dead, But It Should Be Worried
How a genuine 1M context window flips the default assumption on retrieval.The Benchmark Scepticism: What We Don’t Know Yet
All V4 numbers are internal only. No independent evals published yet.The UK and European Angle Nobody Is Writing
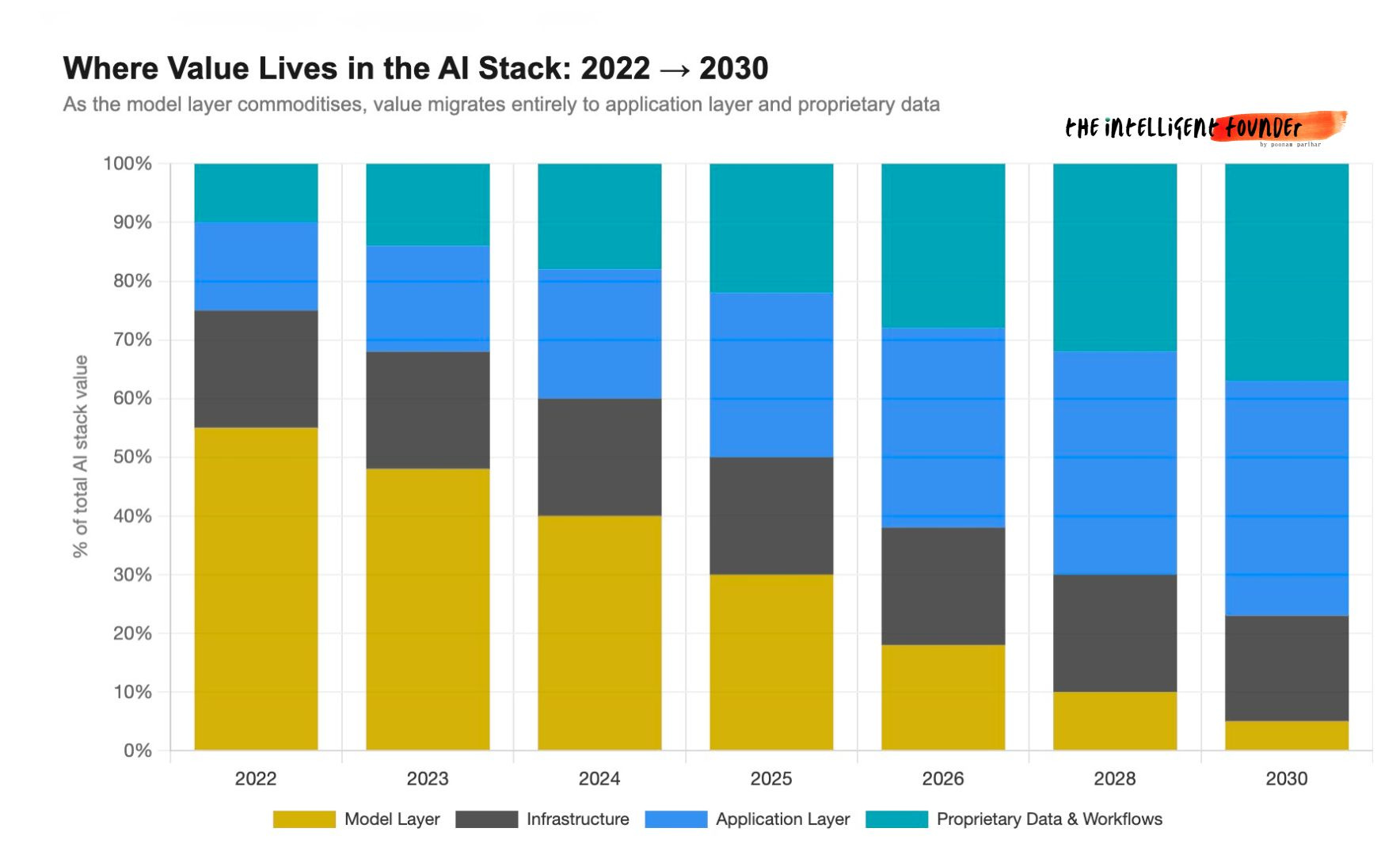
ICO guidance, UK GDPR, and why open weights create a new sovereignty option.The Real Strategic Insight: The Race to the Bottom Is Actually a Race to Irrelevance - For the Model Layer
Commoditization, the value migration to application layer and data, and the question you should actually be asking.
Section 1 - The Scorecard

SO the technical specs haven’t changed. Engram conditional memory, DSA sparse attention, MoE-at-scale, all are in the final release.
V4-Pro ships at 1.6T total parameters with 49B active per token.
V4-Flash at 284B total/13B active.
The 1M token context window is real and live from day one, not a roadmap item.
The “track Chinese pricing as your absolute cost floor” argument was the right call. Official launch pricing:
$0.03/1M cached input tokens, $0.50/1M output tokens, against Claude Opus at roughly $25/1M output.
And, that’s a structural shift in inference economics. Its no longer projected. its confirmed.
DeepSeek also continued its open-source commitment, so weights are live on HuggingFace, Apache-style licensing, same playbook as V3.
It however arrived 6 weeks late, and this actually matters more than the calendar slip, the reason for the delay is one of the most consequential technical and geopolitical stories in AI right now.

What I got wrong ( not wrong wrong) in my previous deep dive is by omission: the “preview” qualifier. What launched today is explicitly a preview release, not GA. so still holding back? - but the API is live and weights are downloadable, but production SLAs, rate limits, and full regional availability are still rolling out. so If you are making enterprise integration decisions today, treat it as early access, not a stable dependency.
Section 2 - What the Internet Is Actually Saying
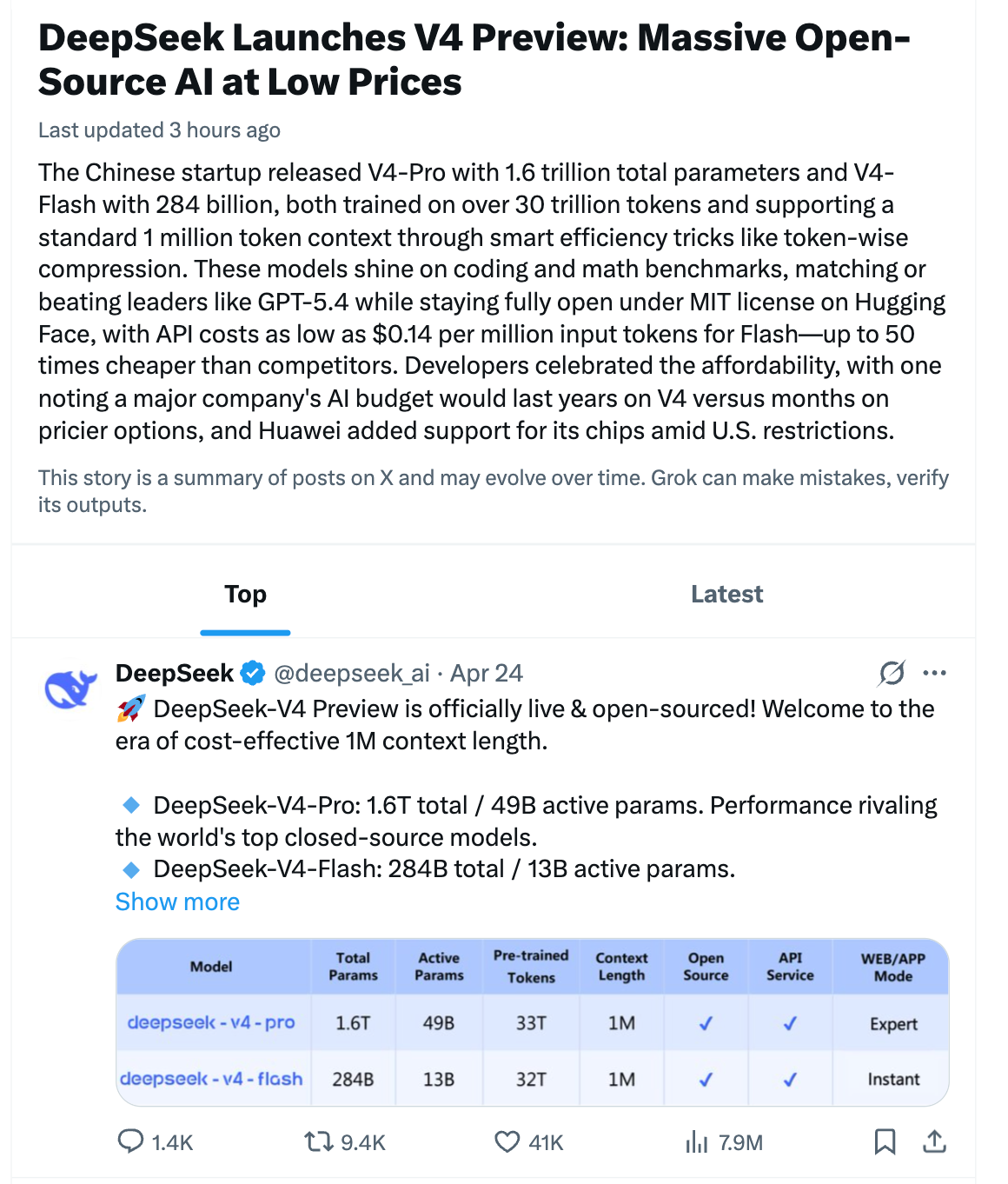
The launch post from DeepSeek’s own Deli Chen is worth reading in full: “484 days later, we humbly share our labor of love. As always, we stay true to long-termism and open source for all. AGI belongs to everyone.”
Couple of statements from twitter -
Developer Theo (@t3.gg) had the most honest practitioner reaction: “Never taking vacation ever again.” Six words that captured exactly how the AI builder community feels right now.
The competitive shade was sharp. One widely-shared post framed it bluntly: “A Chinese company facing chip restrictions can train this. But xAI can’t even get SOTA with a million H100 equivalents.”
The cost framing circulating most widely: “DeepSeek V4 is now the cheapest SOTA model at 1/20th the cost of Opus 4.7. If Uber used DeepSeek instead of Claude, their 2026 AI budget would have lasted 7 years instead of only 4 months.”
On Hacker News the context window is dominating: “If the weights drop with a real 1M context that isn’t a lobotomy past 200K, this is a bigger deal than V3 was.” On r/LocalLLaMA: “If this is real, the entire RAG category has to be rewritten this year.” Both correct - we’ll come back to RAG.
To reiterate the sentiment in most straightforward way, the launch has reset expectations about how fast the ground can move under working builders, and the implicit conclusion is that “slow cycles” on strategy or shipping are no longer viable.
On the competitive side, commentators are highlighting a deeper asymmetry. for example, a lab operating under export controls has managed to train a frontier‑class model, while better‑funded Western labs have struggled to translate vast GPU budgets into clearly superior state‑of‑the‑art results ( Hold on for the Chip story a minute I am coming to that) . That is being read less as an anecdote and more as evidence that capital and hardware alone are no longer a sufficient moat.
Cost discussions have converged on the same point. V4 is being treated as the new effective price floor for frontier‑grade capabilities, with per‑token economics implying that what looked like a one‑year AI budget on premium closed models now stretches to a multi‑year runway on this stack.
For enterprises, that reframes AI line items from “discretionary experiment” to “infrastructure‑level commitment” and forces a rethink of vendor concentration risk.
In technical communities, attention is focused on the 1M‑token context window as expected, but whether it delivers usable recall beyond the usual 200K–300K degradation point. If that holds, the consensus is that many retrieval‑augmented generation pipelines become optional rather than mandatory, with a likely shift from “design around RAG” to “justify RAG only where latency, privacy, or corpus size truly demand it.
DeepSeek founder Liang Wenfeng apparently framed the company’s posture simply: “The whole world should use a 1.6T model for free.”
That is either a genuinely held belief or the most effective marketing line in AI this year. Possibly both.
Section 3 - The Competition
In the six weeks between my March piece and this morning, the entire frontier has moved. so anyone treating the 1M context window as DeepSeek’s unique differentiator is totally wrong. because It isn’t. not anymore.
A quick look at who else got to the 1M number.
Anthropic went GA on 1M token context for Claude Opus 4.6 and Sonnet 4.6 on March 13 - the day after my original article published. and with no price increase.
NVIDIA shipped Nemotron 3 Super on March 11 - a 120B MoE model, 12B active parameters, fully open-weight, with a 1M token context window, 5x throughput improvement for agentic workloads, and free tiers on OpenRouter. It scores 60.47% on SWE-bench and is explicitly designed for multi-agent systems. This launch got a fraction of the coverage it deserved. ( I covered this in a short AIU essay )
Alibaba’s Qwen 3.6 Plus also dropped as a free preview on March 31, formally announced April 2. 1M context by default, hybrid linear attention plus sparse MoE architecture, sitting at #2 on OpenRouter for coding. Free during preview. I haven’t looked in to this really but its worth looking at.
OpenAI launched GPT-5.5 day before yesterday on April 23. ( thats just the day before DeepSeek V4.) Focused squarely on agentic capabilities: complex goal reasoning, tool use, autonomous workflow execution, matching GPT-5.4 on latency while operating at a higher capability tier. Two frontier model drops in 24 hours, both targeting agentic AI. The race for the agentic layer is the actual battleground right now.
The landscape today: ModelContextOpen SourceInput Cost/1M
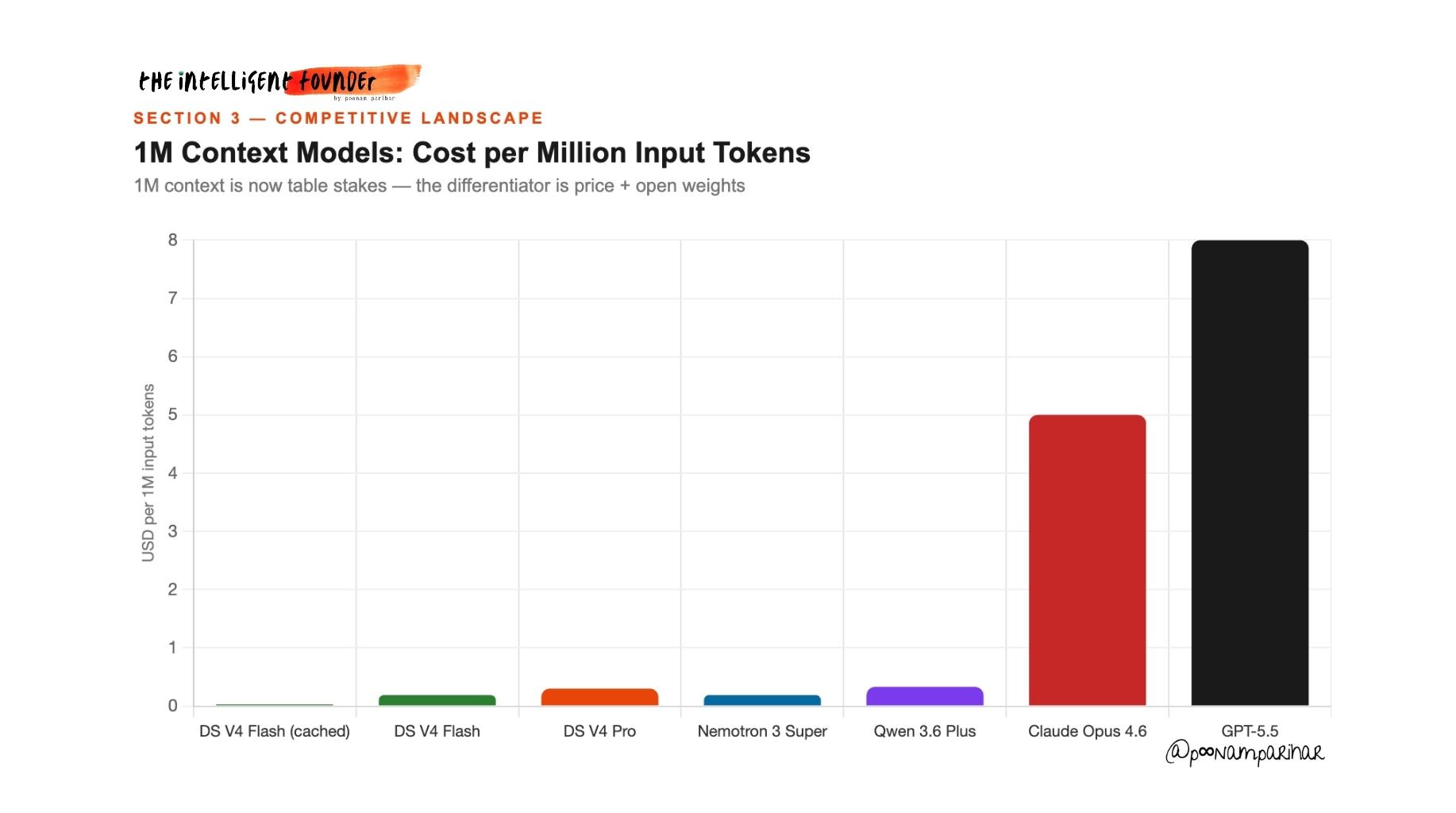
The 1M context window is now a commodity feature. What differentiates V4 is the combination of open weights, frontier-class claimed capability, and that pricing floor, together, not individually.
Section 4 - The Chip Story
There are two claims in circulation that look contradictory but actually aren’t.

Lets take a look at the full timeline -
Reuters, February 24: A senior Trump administration official confirmed DeepSeek trained V4 on Nvidia’s Blackwell chips, which was a direct violation of US export controls. The chips were reportedly acquired via third countries, purchased legally where permitted and then were moved into China.
The Information / Reuters, April 3: DeepSeek spent months rewriting its entire model stack from Nvidia’s CUDA framework to Huawei’s CANN framework. V4 is designed to run inference on Huawei Ascend 950PR chips. That migration is why the model was late.
Trained on smuggled Blackwells. Deployed on Huawei?
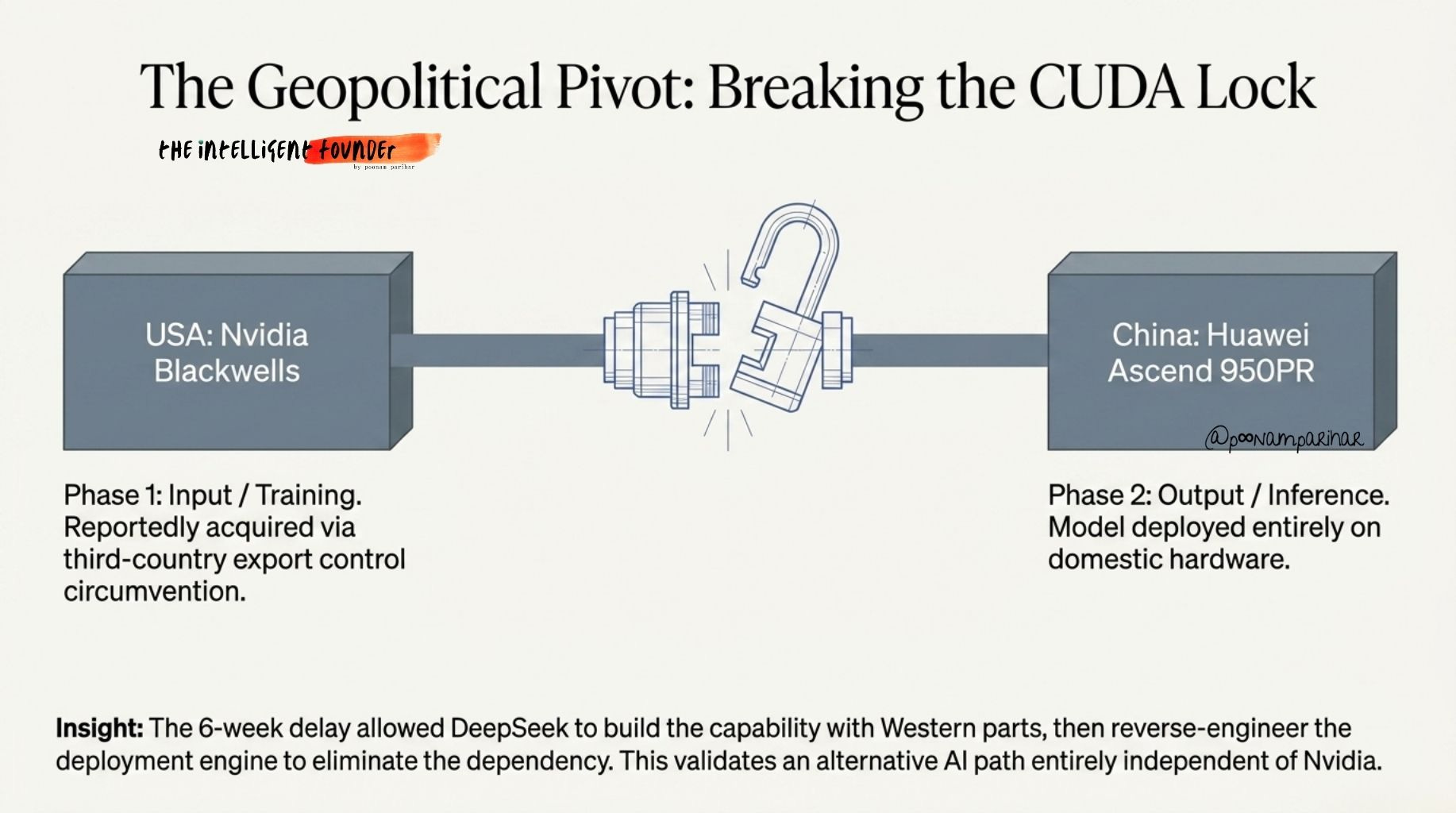
These are not contradictions. What makes this remarkable is that DeepSeek may have used American silicon to build the capability, then ported it to domestic Chinese hardware to eliminate the ongoing dependency. You build the car with foreign parts, then reverse-engineer the engine so you never need those parts again.
Nvidia CEO Jensen Huang addressed this directly on the Dwarkesh Podcast earlier this month, calling the scenario “a horrible outcome” for the United States.
His reasoning?
he was not primarily worried about current performance gaps. He argued that even with inferior chips, China can compensate with “abundant energy” and a “large pool of AI researchers.” If V4 performs well on Ascend chips, it validates an entirely alternative path for AI development that depends on Nvidia at no point in the supply chain. That is the CUDA lock broken. That is what Huang was actually warning about.
So In simple terms, this whole chip story is a reminder that hardware power and smart engineering can’t be fenced in by policy forever. What matters now is that frontier‑level AI is escaping its old dependencies. and for founders and builders, the takeaway is, to assume the barriers you thought protected you, are already gone.
Section 5 - Learning from the Enemy. AI's Unresolved IP War!
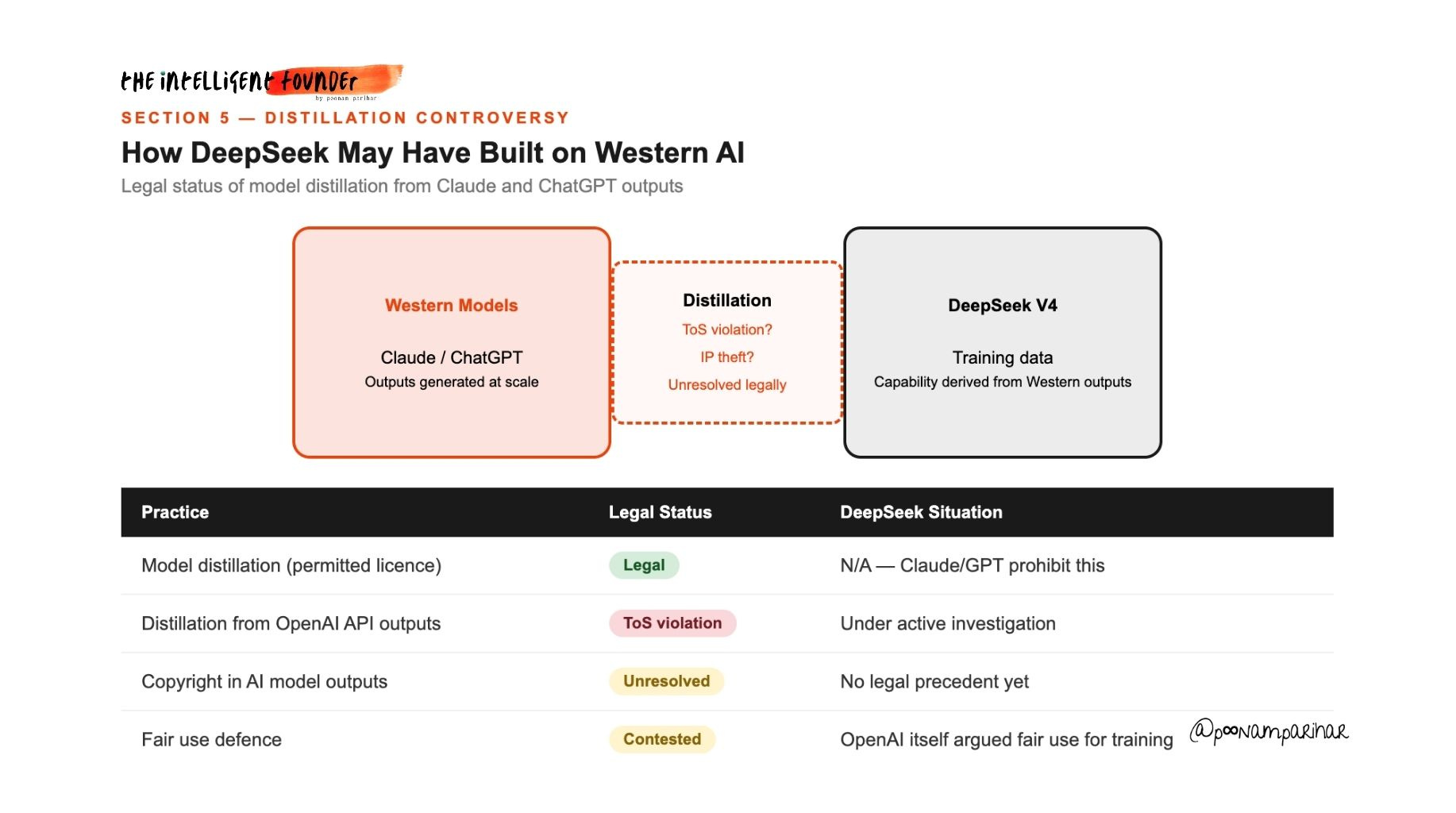
OpenAI has been investigating whether DeepSeek used ChatGPT outputs to train its models since early 2025. Model distillation, generating responses from a stronger model to train a weaker one, is technically normal and widely used. The legal question is entirely about license terms and whether terms of service were violated.
OpenAI’s terms explicitly prohibit using ChatGPT outputs to train competing models. Anthropic’s terms are similar too. Reports suggest that DeepSeek circumvented usage limits to extract training signal from Claude at scale. Whether this constitutes IP theft remains legally unresolved.
AI model outputs may or may not qualify for copyright protection.

China localizing the hardware stack while extracting the knowledge stack from the West, The US-China Security Commission framed this as a structural paradox. For builders using V4 today, it is worth knowing that the model’s capability may partly reflect outputs from models you are also paying for.
Section 6 - The Multimodal Blindspot: This Is Not a Text Model
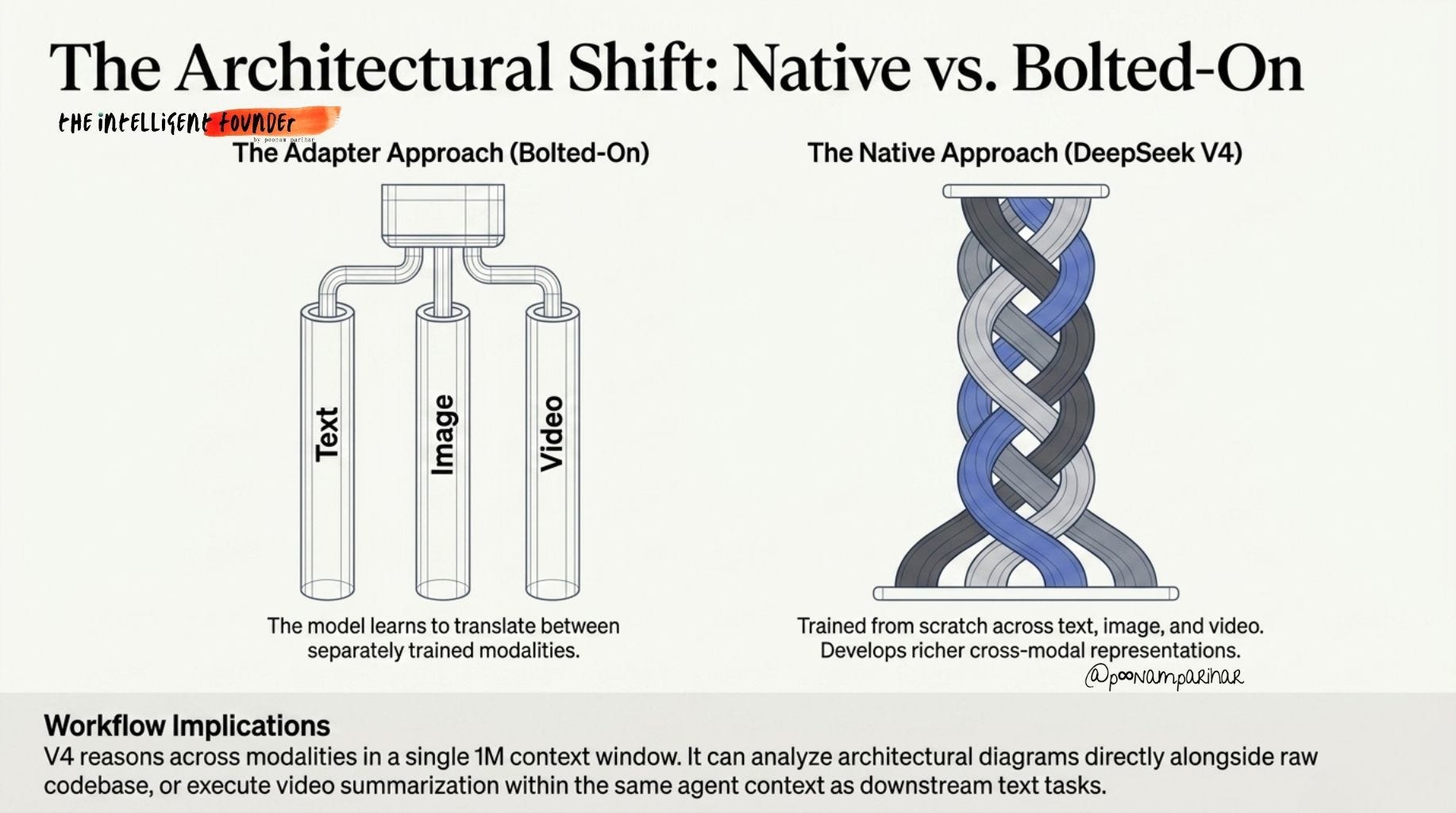
V4 is a native multimodal model, meaning text, image, and video were all trained together from scratch during pre-training, not bolted on via adapter layers after the fact. This is an architectural distinction that matters.
When vision capabilities are added post-training via adapters, the model learns to translate between separately trained modalities. When integrated from the start, the model develops richer cross-modal representations, it reasons across modalities rather than just switching between them.

Audio processing is still unconfirmed, but text, image, and video generation in a unified 1M-context model is a genuinely new capability surface.
The practical implications nobody is discussing today?
