

$12 Billion for a Fine‑Tuning API?
Mira Murati, Thinking Machines, and Tinker API. the one AI Bubble story that went largely unnoticed in 2025, plus why it actually matters!


Fine‑tuning infra is a genuine bottleneck
Fine‑tuning infra is one of the many hard AI‑infra problems. It sits in the model‑development / personalization layer of the AI stack. it comes after a foundation model has been pre‑trained, and before that adapted model is deployed and served to users, as the step where you specialize a generic LLM with your own data, tasks, and tone. Beyond fine‑tuning, teams still struggle with data pipelines, GPU‑efficient serving, security/compliance, observability, and integration into messy legacy systems.
But fine‑tuning infra is one of the main pain point, because most teams don’t struggle with ideas for customizing models, they struggle with the plumbing needed to actually run those experiments. Fine‑tuning large LLMs means coordinating high‑end GPUs, fast storage, and low‑latency networking while keeping utilization high and costs under control, which demands deep distributed‑systems expertise that many orgs simply don’t have. Even “lighter” approaches like LoRA still hit GPU memory limits, data‑pipeline bottlenecks, and orchestration complexity, so without a solid infra layer, teams waste 30–50% of training time on underutilized hardware and operational glitches instead of iterating on models.
But can a narrow tool, ( not a full platform ) and a small slice of AI infrastructure stack justifies a $12B valuation?
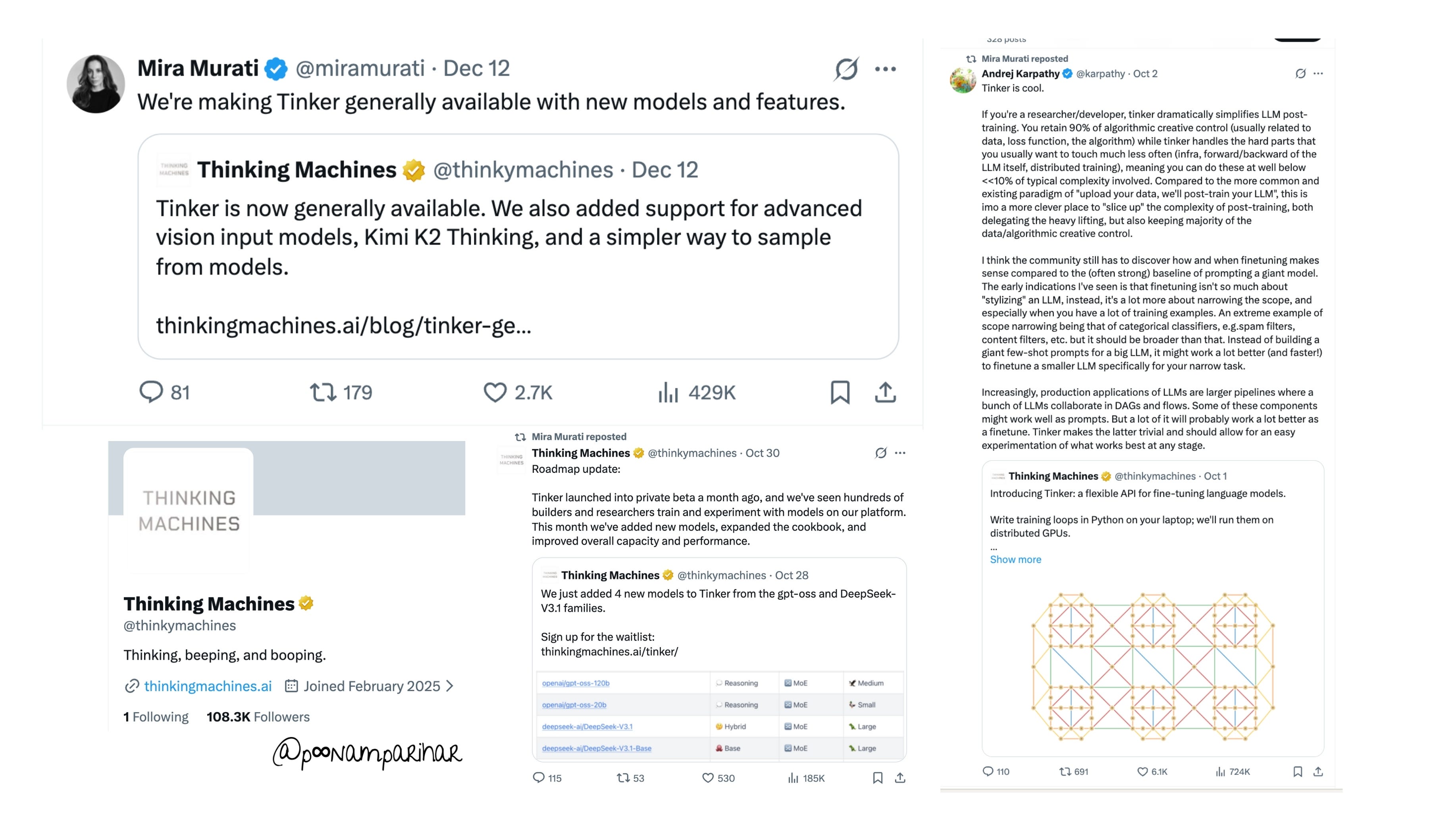
The last time Mira Murati really broke through my news feed on linkedIn was in August 2025. Fortune ran and amplified MIT’s NANDA report claiming that around 95% of generative‑AI pilots at companies were failing, a story that went viral for its stark headline about the ‘GenAI divide’ and that was before anyone could get their hands on the report to analyze the sample data size. around the same day another Fortune piece from few weeks ( end of June - earlier July timeline) before on Thinking Machines’ $2 billion seed round at a roughly $12 billion valuation showed up and was presented as a milestone / record breaking / largest raise for a female founder in frontier tech. No sign of AI boom still being alive on this one, while the NANDA piece became the go‑to reference for skepticism about enterprise AI, and overall AI hype.
So when I saw bunch of updates on Tinker, including the latest one from 2 days ago, about both Tinker’s general availability and Mira Murati eyeing for $50B valuation, I wanted to dig deeper.
SO What is Tinker Exactly?
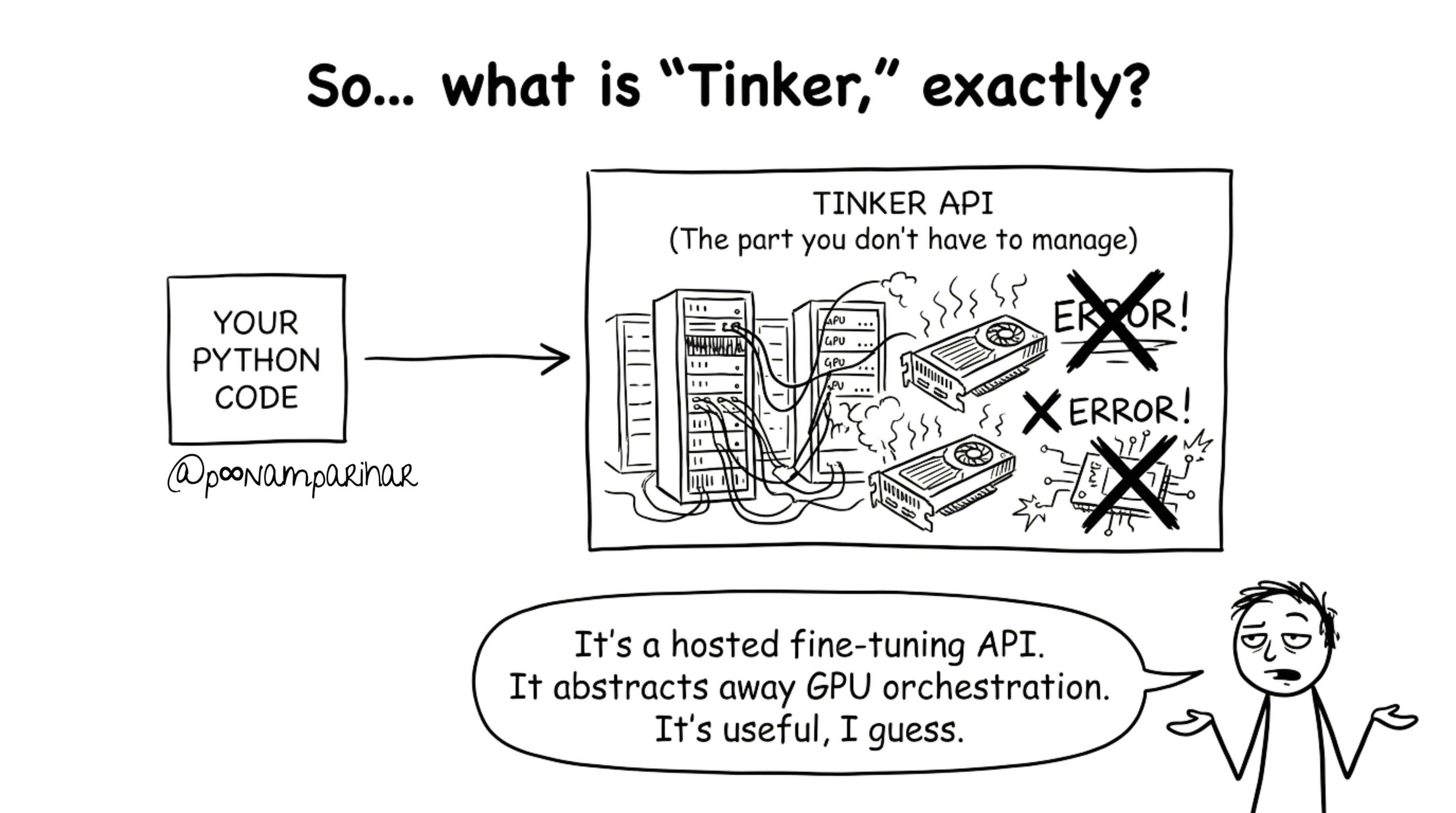
If you ask people outside the AI infra bubble what Tinker does, most won’t know. And that’s partly because the answer is boring: it’s an API for fine-tuning and training large language models.
Fine-tuning which I already explained above, and that might have bored you already? - is one of the least sexy parts of AI. It’s not building a frontier model. It’s not creating the next GPT.
It’s the infrastructure work that happens after a model is built
the process of taking a base model and adapting it for a specific task, domain, or organization.
